


Kafka, a single platform for processing real-time data sources was developed by LinkedIn in 2010 and has been a top-level Apache project since 2012. It is a highly scalable, robust, durable, and fault-tolerant publish-subscribe event streaming platform.
What Is Apache Kafka?
Apache Kafka is a publish-subscribe messaging system and a strong queue that can manage a large amount of data and allows you to transmit messages from one end-point to another. Kafka can be used to consume messages both locally and remotely.
To prevent data loss, Kafka messages are saved to disk and replicated throughout the cluster. The ZooKeeper synchronization service provides the foundation for Kafka. For real-time streaming data processing, it works extremely well with Apache Storm and Spark.
Apache Kafka Terminology
Let’s take a look at basic Apache Kafka terminologies that are key to knowing when working with Kafka.
Producer
A producer creates a lot of information and pushes them to Kafka.
Consumer
A consumer can be any sort of utilization that peruses information from the line.
Topic
Kafka allows you to mark information under a class called a topic. Consumers can buy into explicit topics they need to peruse information from. Producers can compose information on at least one topic.
Partition
A topic can have various partitions to deal with a bigger measure of information.
Replicas of partition
A replica is a partition's reinforcement. Apache Kafka means to be a strong informing framework, so it requires to have reinforcements. Kafka precludes perusing or composing information to replicas. Replicas essentially forestall information misfortune — they have no different obligations.
Informing System
An informing framework moves information between applications. This permits an application to zero in on information, irrespective of how information gets shared.
There are two sorts of informing frameworks:
- Point-to-Point system
- Publish-subscribe messaging system
The classic example of a point-to-point system is where producers persist data in a queue. Only one application can read the information from the queue, and once read, the message is removed from the queue.
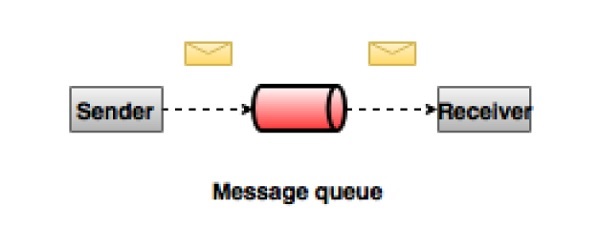
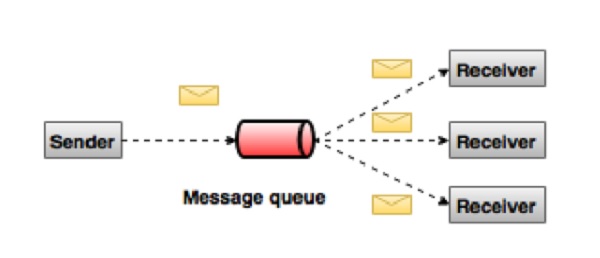
The classic example of a publish-subscribe messaging system is Apache Kafka. Consumers can subscribe to multiple topics in the message queue. But, they only receive specific messages that are relevant to their application.
Broker
As the name proposes, a broker goes about as a facilitator among purchaser and merchant. A Kafka broker gets messages from producers and stores them on its disk. Likewise, it works with message recovery.
In this article, we will take a look at Producers and Consumers in a bit more detail!
PRODUCER
A Kafka producer's main job is to take producer properties and record them as inputs, then write them to an appropriate Kafka broker. On the basis of partitions, producers serialize, partition, compress and load balance data across brokers.
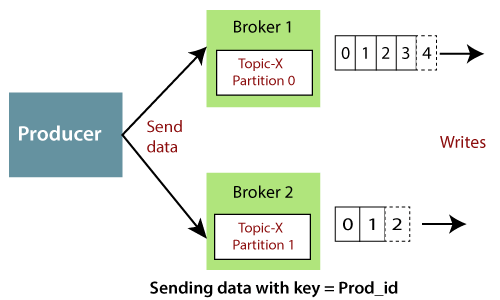
The producer must first establish a connection with one of the bootstrap servers before sending the producer record to an appropriate broker. The bootstrap-server produces a list of all available brokers in the clusters, as well as metadata such as topics, partitions, and replication factors. The producer determines the leader broker that hosts the producer record's leader partition and writes to the broker using the list of brokers and metadata details.
Duplicate message detection through Kafka producer
When Kafka commits a message but the acknowledgment is never received by the producer owing to network failure or other difficulties, the producer may send a duplicate message. Kafka 0.11 and later track each message based on its producer ID and sequence number to eliminate duplicate messages in the above scenario.
When a duplicate message is received for a committed message with the same producer ID and sequence number, Kafka will recognize the message as a duplicate and will not commit it again; however, it will send an acknowledgment to the producer so that the message can be treated as transmitted.
Important Producer Parameters:
1. Acks
The acks option determines how many acknowledgments the producer needs from the leader before a request is considered complete. This option specifies the producer's level of durability.
Max.in.flight.requests.per.connection
The maximum number of unacknowledged requests a client can send before being blocked on a single connection. If this option is greater than one, pipelining is employed when the producer sends the aggregated batch to the broker.
This improves throughput, but it also raises the chance of out-of-order delivery due to retries if any sends fail (if retries are enabled). Excessive pipelining, on the other hand, reduces throughput.
2. Compression.type
Compression is a crucial aspect of a producer's job, and the pace of various compression techniques varies greatly.
The compression.type property can be used to specify the type of compression to employ. It supports conventional compression codecs ('gzip', 'snappy', 'lz4'), as well as 'uncompressed' (the default, which is equivalent to no compression) and 'producer' (which is equivalent to no compression & uses the compression codec set by the producer).
3. Batch.size
Larger batches have better compression ratios and throughput, but they also have a longer delay.
4. Linger.ms
Setting linger.ms values aren't easy; you'll have to experiment with different scenarios. This parameter doesn't seem to have much of an effect on minor events (100 bytes or less).
Workflow of a producer
1. Serialize
The producer record is serialized in this stage using the serializers given to the producer. The serializer is used to serialize both the key and the value. String serializers, byteArray serializers, and ByteBuffer serializers are examples of serializers.
2. Partition
The producer selects which of the topic's divisions the record should be written to in this step. For partitioning, the Murmur 2 algorithm is used by default. Based on the key supplied, Murmur 2 algorithms generate a unique hash code, and the appropriate partition is determined. The partitions are chosen round-robin if the key is not passed.
3. Compression
The producer record is compressed before being written to the record accumulator in this stage. Compression is disabled by default in Kafka producers. Compression allows for speedier data transit between the producer and the broker, as well as during replication.
4. Accumulator of Records
The records are accumulated in a buffer per topic partition in this step. The producer batch size attribute is used to arrange records into batches. Each topic's partition has its own accumulator/buffer.
5. Sender Message
The batches in a record accumulator are categorized by the broker to which they will be transmitted in this stage. According to the batch.size and linger.ms values, the records in the batch are forwarded to a broker. The producer sends the records when either the set batch size or the defined linger time is achieved.
CONSUMER
A Kafka consumer's main responsibility is to read data from a suitable Kafka broker. Understanding Kafka's consumers and consumer groups are necessary before learning how to read data from it.
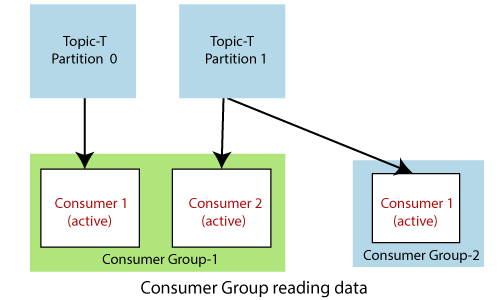
A consumer group is a collection of people who all have the same group identifier. Every record will be given to only one consumer when a topic is consumed by consumers in the same group. If all of the consumer instances belong to the same consumer group, the records will be load-balanced amongst them.
In this manner, you can ensure that records from a topic are processed in parallel and that your users do not step on each other's toes. One or more sections make up each topic. When a new consumer starts, it joins a consumer group, and Kafka ensures that each partition is only consumed by one consumer from that group.
1. Kafka consumer load share
Within a consumer group, Kafka consumer consumption divides partitions across consumer instances. Each member of the consumer group is the exclusive owner of a "fair share" of partitions. This is how Kafka balances the load of consumers inside a consumer group.
The Kafka protocol dynamically manages consumer group membership. A consumer group receives a share of partitions when new consumers join it. If a consumer dies, the remaining live consumers in the consumer group share the partitioning. This is how Kafka handles consumer group failure.
2. Kafka Consumer failover
When consumers successfully process a record, they tell the Kafka broker, which advances the offset.
If a consumer fails before sending the committed offset to the Kafka broker, another consumer can pick up where the previous consumer left off.
Some Kafka entries may be reprocessed if a consumer fails after processing the record but before sending the commit to the broker. Kafka provides at least one behavior in this circumstance, and you need to ensure that the messages are idempotent.
3. Offset management
Kafka stores offset data in the "__consumer_offset" topic. These topics use log compaction, which means that just the most recent value per key is saved.
A consumer should commit offsets after it has processed data. If the consumer process dies, it will be able to restart and resume reading from the offset recorded in "__consumer_ offset," or another consumer in the consumer group can take over.
Multi-threaded Kafka consumer
1. Consumer with many threads
If processing a record takes a long time, a single Consumer can run numerous threads, but managing offset for each Thread/Task is more difficult. Two messages on the same partitions can be processed by two distinct threads if one consumer runs several threads, making it difficult to guarantee record delivery orders without complicated thread coordination. If processing a single task takes a lengthy time, this setup may be reasonable, but try to avoid it.
2. Thread per consumer
Execute each consumer on its own thread if you need to run several consumers. This allows Kafka to provide record batches to the consumer while eliminating the need for offset ordering. Offsets are easier to manage with a thread per consumer. It's also easier to manage failover because Kafka takes care of the heavy lifting.
Benefits offered by consumer group
The following are the benefits offered by consumer groups
1. Each instance receives messages from one or more partitions (which are "automatically" assigned to it), but the other instances will not receive the same messages (assigned to different partitions).
As a result, the number of instances can be scaled up to the number of partitions (having one instance reading only one partition). In this circumstance, a new instance joining the group is idle and unassigned to any partition.
2. Having instances in distinct consumer groups necessitates a publish/subscribe pattern in which messages from partitions are broadcast to all instances in the various consumer groups. The rules are as seen in the second image inside the same consumer group, but across groups, the instances receive identical messages (as shown in the third image).
This is beneficial when the messages included within a partition are of relevance to multiple applications, each of which will treat them differently. We want all of the partition's interested programs to receive the same messages.
3. Another benefit of consumer organizations is the ability to rebalance. If there are enough partitions available (that is, the limit of one instance per partition hasn't been met), rebalancing begins when an instance enters a group. The partitions are redistributed to both the current and new instances. Automatic management of offset commits is provided.
Advantages of using Kafka
Here are a few advantages of using Kafka:
- Kafka is fault-tolerant, distributed, partitioned, and replicated.
- Scalability The Kafka communications system scales up and down without requiring any downtime.
- Kafka uses a Distributed Commit Log, which implies that messages are sent to disk as quickly as possible, and hence are persistent.
- Kafka has a high throughput when it comes to both publishings and subscribing to messages. Even with many TB of communications saved, it maintains constant performance.
- Kafka is extremely fast, with no downtime or data loss guaranteed.
- Kafka enables low-latency message delivery while simultaneously offering fault tolerance in the case of a system failure.
- Kafka is a lightning-fast system that can write 2 million messages per second.
- Kafka saves all data to disk, which means that all writes are saved in the OS's page cache (RAM).
- Transferring data from a page cache to a network socket becomes incredibly efficient as a result.
Conclusion
In the above article, you saw an overview of Kafka's consumer and producer. We hope his article will help you to know about the parameters of producers and producers' workflow.












Leave a Reply